Why Automation is Important
Recently I was grading projects for one of the classes I TA for. To grade the projects I was required to first copy all of the student code into the teachers solution to verify the students completed the assignment correctly. Then I had to open the teachers solution and compile the code. Third and final step was to open the student code and verify they commented it correctly. In total this took about 15-20 minutes to complete all the steps. So for the class size of 27 students I had it would have taken around 9 hours to complete, but I had other work to do and my student employment doesn’t like it when I go over my weekly allotted 4 hours.
One of the most time consuming parts was navigating to each students code, opening each folder, then copying it into the other solution making sure to wipe out all of the previous students code, note each student has a different file naming convention. To shorten this I wrote a batch file, copy all of the contents from the specific student locations and move it to the teachers solution. This wasn’t complete because there was still the previous students code remaining. I then added to the script, before copying remove the previous directories and create new folders. Now I was able to automate one of the steps, this brought me down to 10-15 minutes a student, which takes me down to about 4 hours, not bad for a simple script.
Next issue that came up was I still had to copy my script into the student code, this was a simple fix though just ran a script that would grab the script and move it to each student as I graded them. This shaved off a little more time. I still had to manually open their code to check for commenting. I ended up writing another script that would open all of their source files in notepad++ for me, this cut my time down to 8 minutes. This was about the bare minimum I could get away with because I still had to verify they had comments and that the small game the made worked properly. Now the total time it took me was about 3 and a half hours.
Now let’s look at the cost I saved the school:
- With no automation: ((20 minutes * 27 students) / 60 minutes) * $12.00 = $108
- With copy files automation: ((15 minutes * 27 students) / 60 minutes) * $12.00 = $81
- With copy and open files automation: ((8 minutes * 27 students) / 60 minutes) * $12.00 = $43.20
This shows why automation is important, I cut the cost of grading these projects by $64.80. This may not sound like much but let’s say we have 100 TA’s who can automate in a similar way, now we just saved the school $6480. That number is per assignment assuming 27 students. This is the important part from a business stand point, you can save your company money. From the stand point of a student it is great because I then have more time to work on other projects and side projects.
The most difficult bug of my career
Over the summer of 2013 I decided to take an independent study with one of the faculty at DigiPen, the goal of this independent was a nice introduction to GPGPU (General Purpose computing on Graphics Processing Units). For the nice introduction I decided to take up the graphics related task of Ray Tracing, then from there move it to the GPU using C++ AMP (Accelerated Massive Parallelism) hopefully achieving a real time ray tracer.
Now a bit of back story on the project before the bug. I had written a ray tracer in C++ that ran on the CPU, I did this because having never implemented a ray tracer I needed to know how to do that before I could port it to the GPU. At this point I had used the concept of polymorphism by implementing a parent shape class then allowing sub shapes to write their own ray – shape intersection. For example I was able to support quads, spheres, and boxes. After having that complete I moved onto porting it to the GPU.
This is where problems arose. One big problem I found was the GPU does not support virtual classes which meant my polymorphism just went out the window. To solve this problem I decided rather than having a big branching switch statement on the GPU I would just use one type of object for everything, the same way computer graphics in video games do it, triangles! I added some classes, started reading .obj files exported from 3DS Max, and sending all that information through a pipeline into world space on the CPU. One Ray-Triangle intersection function later I thought everything was implemented and ready to go. I go to run it in debug mode just to make sure everything will run with out crashing, 1500 seconds later I have a nice image the only problem is the object wasn’t there. Some debugging later I found some simple logic mistakes that happened from porting to the GPU, not bad 30 minute fix.
At this point everything should work, right? NO. I had a quad working just fine so the box should be good, right? NO. When I render I end up with something that looks like this mess.

Well that was supposed to be a cube, it somewhat resembles a cube. Now I go through more debugging looking for what could be causing this. Note each time I ran this it took anywhere from 600 seconds to 2000 seconds, so progress was slow. I eventually tracked down an issue with my intersection function that I had no idea how to fix because the math made sense. So a few googles later I find a new Ray-Triangle intersection function that may work, looks nearly identical to my function with one extra if check that determines if the ray and triangle are parallel in which there will never be a collision. Now the problem must be solved, right? NO.
This is where it turns into the hardest bug of my career. I finally decide to switch to an orthographic view to make the math on paper easier as well as debugging any problems I may have with the normals of the object. First I went back to the quad, 2 triangles are much more simple that 12 and there are less calculations I have to do on paper, awesome. Running through the math and taking everything step by step, looks good, everything seems to be working. Now let’s fire up Release mode, boom less than 1 sec later rendering is complete, time to have a look at the image, a nice shiny red quad. Feeling good I decide to try the cube again, same results a before.
Why oh why could it be broken again. Well I noticed there were optimizations turned on in Release mode, maybe that is the issue. After disabling that it now takes about 3 sec to render and still doesn’t work. Back to the drawing board. Going through the list of things that could be wrong, uninitialized data, an issue with the copy to the GPU, hardware issue, hardware timeout, logic issue, or the compiler is optimizing something key away.
Starting with the hardware issue I grabbed some other DirectX 11 devices and ran my code on that. Being I am using a Intel HD 4000 onboard graphics chip when running my code on a ATi 5870 the performance boost was nice to see, all rendering times were sub 1 second. Sadly though hardware was not the issue, I got the same results from every device I tried it on. From here I decided there was one way I could test for a hardware issue in Release mode but it would be as slow if not slower that Debug, that solution is run it on the DirectX Reference Accelerator. For those who do not know what that is, it is an accelerator that emulates the GPU on the CPU which eliminates the GPU hardware issue. One interesting thing happened, it worked. Sadly I needed to figure out why the version running on the actual hardware was not working.
Since the big issue with Release mode is I cannot debug anything that is on the GPU I have trouble finding where the problem even is. I also do not have the ability to printf debug my code on the GPU either. Basically there is only one way for me to get information from the GPU in Release mode, write different information to the texture I am using. I ended up deciding I would give each of the 12 triangles a unique color, I could then see what ray is colliding with what triangle. Here is what I got from Debug/Reference Accelerator.

The same object but in Release mode.

In debug you can see the 2 triangles that make up the front face of the cube. Where Release mode looks like colorful noise. What I first thought was able to be repeated it turns out is random, every iteration it runs the noise changes making debugging even harder. Upon closer inspection of the noise I realized it isn’t just single rays/pixels intersecting with the wrong triangle it is actually groups of them which is very odd. Also depending on how the computer is feeling either the left or right side will have many more correct collisions (as seen by the large purple bar on the right in the Release picture).
Now I can get a bit of information from the GPU, I decide it must be uninitialized data somewhere. I go to every class that communicates with the GPU in any way and make sure there is a constructor, destructor, copy constructor, and assignment operator. In all of these operators I make sure all the data is initialized to something, that way there can be no garbage data. Well after running it again, no luck. If there is any uninitialized data I have no idea where it could be at.
I’m 4 days into this bug and still no progress to fixing it. I decided time to check to make sure all the data is being copied to the GPU correctly, I used the quad and save all the 2 triangles in a different data structure and then pass that to the GPU. Once the info is on the GPU I check if it matches the 2 triangles, if just the first triangle is wrong I will see red, if just the second triangle is wrong I will see green, and if both are wrong I will see yellow, otherwise I will just see white. Well as you can guess I saw a whole lotta white.
Last thing I can think of is a logic issue somewhere. To test the logic I copy and paste all my GPU code into my CPU ray tracer in hopes that the same problem will occur but I can then debug or at least printf debug the issue. I figured I would just go all out and not even try to test a quad and then test the box, I went straight to the box and well see for your self what happened.

It worked… That is one shiny cube made out of 12 triangles with correct normals (as seen by the reflections) being rendered.
At this point I have completely run out of ideas and my deadline is fast approaching to implement a small game in a realtime ray tracer. I decided to switch back to simple spheres and if I have time I will try to hard code a quad as well. This bug sets a few new records for me, I have never spent a full week working on one single bug, never have I ever run out of ways to debug something, I also have never left a bug this big unsolved. My curiosity is burning to know the answer as to why it is broken. I hope once I complete my goals I will return to this bug and determine the root cause.
My thoughts for future debugging, I will output ray info, triangle info, which triangle has collided, as well as the final result all on different textures. I am going to also install Windows 8 and Visual Studio 2012 on another computer. I also want to install Visual Studio 2013 when my computer updates to Windows 8.1 or when I have time to install the Windows 8.1 release preview.
I hope you have enjoyed reading about the most difficult bug I have ever come across. I am going to be cleaning and commenting the code soon, I will then make the bit bucket repository public for everyone to try to debug as well as see what C++ AMP can offer. Plus you can even play my small game when it comes out.
UPDATE: Thanks to Cody Pritchard I discovered it was a race condition with a variable I over looked, which also happens to be the only variable I write to… Thanks Cody!
Simple Object Factory In C++
Very recently I worked on the game Wub Wub Racer Magic, this was a team project with a total of 4 devs. I did most of my work on graphics and debug tools but reworked a lot of the core engine, while doing this I came across some nice factory code that I really liked. It is a very simple and elegant basic factory system for creating any object. I am currently working on a Ray Tracer which I used this factory in. Here is the code.
This is the header file
#pragma once
#include <hash_map>
#include
class Prototype
{
public:
virtual void* CreateType(void) = 0;
};
template
class TypedPrototype : public Prototype
{
public:
void* CreateType(void)
{
return new T();
}
~TypedPrototype(void)
{
delete T;
}
};
struct ShapeFactory
{
static void RegisterPrototype(const char* name, Prototype* object);
static stdext::hash_map<std::string, Prototype*> shapes;
static void CleanFactory(void);
};
And this is the cpp file
#include "Factory.h"
stdext::hash_map<std::string, Prototype*> ShapeFactory::shapes;
void ShapeFactory::CleanFactory(void)
{
for(auto it = shapes.begin(); it != shapes.end(); ++it)
{
delete it->second;
}
shapes.clear();
}
void ShapeFactory::RegisterPrototype(const char* name, Prototype* type)
{
if(shapes.find(name) == shapes.end())
{
shapes[name] = type;
}
else
{
delete type;
}
}
So what is this code doing? Well lets start with the prototype class this is just a placeholder that we can inherit from to get the results we want. The true class we care about is TypedPrototype which inherits from Prototype but the difference is this one has the extra template parameter which allows us to create objects of any type all based off of the name we assign to it. Now onto the ShapeFactory (it is called shape factory because I use it for various shape objects), there is the most basic functionality included in this class, RegisterPrototype which takes a name and an instance of the type; CleanFactory which frees all memory from the factory and wipes out the database, and last but not least the hash map that contains the data types.
Now a quick look at the implementation, it is all very very simple which is why there are no comments but a quick overview of the stuff that has been assumed. Firstly the Prototype pointer passed to RegisterPrototype is assumed to be allocated and not NULL, a NULL check could be added very easily though. Also it is assumed that this memory should be handled by the factory in which if a duplicate exists it will free the memory and leave the first item intact.
ShapeFactory::RegisterPrototype("Sphere", new TypedPrototype<Sphere>());
ShapeFactory::RegisterPrototype("Plane", new TypedPrototype<Plane>());
This is an example of how I use it in code, now when I read in from a file I can create any object the factory knows of by simply calling CreateInstance.
Correct Horse Battery Staple
Excited to attempt this challenge, maybe even generate my new password out of it!
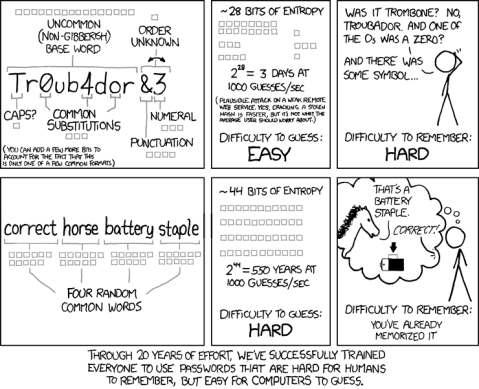 In his 936th xkcd comic strip, Randall Munro described what is wrong with common passwords and suggested a method of passphrase generation that is simpler to use and provides greater security. Unfortunately, I know of no popular websites that permit xkcd-style passphrases. I do still recall, however, the xkcd-style passphrase that CompuServe assigned me about twenty-five years ago (does anyone else remember upgrading from a 1200 baud modem to 9600 baud?)
In his 936th xkcd comic strip, Randall Munro described what is wrong with common passwords and suggested a method of passphrase generation that is simpler to use and provides greater security. Unfortunately, I know of no popular websites that permit xkcd-style passphrases. I do still recall, however, the xkcd-style passphrase that CompuServe assigned me about twenty-five years ago (does anyone else remember upgrading from a 1200 baud modem to 9600 baud?)
Your task is to write an xkcd-style passphrase generator. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
The only hard part of this exercise is creating a word list, as standard system dictionaries include strange and uncommon words that wouldn’t work well. I found a list of the 5000 most common English words at English Club, removed…
View original post 206 more words
Programming Interview Study Guide Part 1: Trees and Time Complexity
As I work on preparing for interviews to get a summer internship I find my self looking over the same things over and over. For this reason I have decided to post my notes as they may help someone else preparing for interviews. This study guide assumes you have a general knowledge of trees and just need a review or something to study off of. Should you come across any mistakes I have made comment or email me as soon as possible so I can fix them for everyone.
Time Complexity of Common Data Structures
|
Data Structure |
Search |
Delete |
Add |
|
Binary Search Tree (Balanced) |
O(log N) |
O(log N) |
O(log N) |
|
Binary Tree |
O(N) |
O(N) |
O(N) |
|
Unsorted Array |
O(N) |
O(N) |
O(1) |
|
Sorted Array |
O(log N) |
O(N) |
O(log N) |
|
Linked List |
O(N) |
O(N) |
O(1) if not sorted else O(N) |
|
Doubly Linked List |
O(N) |
O(N) |
O(1) if not sorted else O(N) |
|
Stack Push front pop front |
N/A, could be O(N) using a modified stack |
N/A See Pop |
O(1) |
|
Dequeue/Queue Push back, pop front |
Pop: O(N) can be O(1) using circular array |
N/A See Pop |
O(1) |
|
Priority Queue/Heap |
Pop: O(1) |
N/A See Pop |
O(log N) |
|
Hash Map |
O(1) |
O(1) |
O(1) |
Trees
Recursive Traversal
Pre-Order Traversal:
Do operation on current node Move Left Move right
Post-Order Traversal:
Move Left Move Right Do operation on current node
In-Order Traversal:
Move Left Do operation on current node Move Right
Level-Order Traversal:
Get Height of Tree
For i less than height of tree:
Call LevelOrder(Node, level)
LevelOrder(Node, level)
if level is 0 then do operation on node
else
LevelOrder(node left, level - 1)
LevelOrder(node right, level - 1)
Iterative Traversal
Pre-Order Traversal:
Check if tree exists
Push root onto stack
While stack is not empty
Node equal top
Pop top
Do operation on node
If right is not NULL then push right onto stack
If left is not NULL then push left onto stack
End while
Post-Order Traversal:
Check if tree exists
Create iterator pointer and set it to root
While iterator is not NULL or stack is not empty
If iterator is NULL
While stack is not empty and iterator is equal to stack top right
Iterator equals top
Pop element
Do operation on node
End while
Else
Push iterator
Iterator equal iterator left
In-Order Traversal:
Check if tree exists
Create iterator pointer and set it to root
While iterator exists or stack is not empty
If iterator is not NULL
Iterator equals top
Pop element
Do operation on node
Iterator equals iterator right
Else
Push iterator
Iterator equals current left
End while
Level-Order Traversal:
Check if tree exists
Push root onto queue
While queue is not empty
Get top
Pop top
Do operation on node
If left is not NULL push onto queue
If right is not NULL push onto queue
End while
Height of a Tree
Using simple recursion
Height(Node) If node equals NULL then return -1 Else return 1 + max(Height(node->left), Height(node->right))
Rotations used for Balancing
Rotation Right:
temp = node node = node left node left = node right node right = temp
Rotation Left:
temp = node node = node right node right = node left node left = temp
Other Notes
Binary Tree vs. Binary Search Tree
Binary Tree is just a tree where each node has 2 children
Binary Search Tree follows the rule all left children are less than the current node and all right children are greater
Never assume someone means either of these always ask them to specify which they mean
Balanced Tree
A balanced tree is merely a tree with a height that never varies by more than one on the leaves
Hope this is helpful I will continue to post more of my notes as soon as I have some more free time.
Awesome article by my friend, shows the power of Python.
This post is a double header. I want to give a brief introduction to numerical integration, as well as rave on about how convenient Python is for small projects.
I recently became familiar with Python in order to write logic quicker than C++ allows, and to understand the simplicity of a scripting language. Unfortunately I don’t have any large Python projects to show yet, but I have found it to be extremely helpful when tackling math-coding assignments.
Last semester I used C++ for coding assignments in Linear Algebra. I coded row reduction, a determinant calculator, inversion checking, and more. There is no doubt that C++ is a beautiful language that I could rant about forever, but for short assignments like these, the syntax in C++ tends to become sloppier than it needs to be for a task so simple.
Below is my most recent assignment from MAT357, Numerical Analysis. We…
View original post 514 more words
Python Practice With Project Euler
I recently learned Python through the website Codecademy. This is a great way to learn a new language with many exercises to do and projects at the end of each lesson, but I needed more. So I looked back to Project Euler. I have tried some of the challenges featured on Project Euler using C and C++ for some challenges this works very well others however I run into issues with precision/overflow to counteract this I could research how variable precision works, then implement it in C/C++ and then finally get to the original problem. This would be a great opportunity to learn variable precision or I could get familiar with a new language in this case I chose to become more familiar with Python.
One of the problems I did was challenge number 4: Find the largest palindrome made from the product of two 3-digit numbers. Here is my solution.
def is_num_palindrome(num):
string = str(num)
if string == string[::-1]:
return True
else:
return False
def find_palindrome_product():
list = []
for i in range(100,1000):
for j in range(i,1000):
num = i * j
if is_num_palindrome(num) == True:
list.append(i * j)
return max(list)
I then have to just call find_palindrome_product and it will give me a list of all the palindrome numbers that can be made from multiplying 3 digits together. This one can be done in C/C++ but python makes the solution compact and elegant such as being able to convert the number to a string and then check if it is a palindrome in one line.
I also did challenge number 5 which is: What is the smallest positive number that is evenly divisible by all of the numbers from 1 to 20?
def smallest_multiple():
i = 21
while True:
for j in reversed(xrange(1,20)):
if i % j != 0:
break
else:
return i
i += 1
This solution took me a few tries, I had the solution from the beginning but it took a while to run so I tried optimizing it a bit. My optimization was start the loop that checks if it is evenly divisible from 20 and work down to 1 because odds are it will fail at the upper range rather than the lower range. This helped the speed out a bit. I am going to continue to do challenges on Project Euler I hope to become much more familiar with Python by the end of it.
Update of of what I am working on
Hello World,
I just wanted to let you all know what I am currently working on. I have an assignment for a class which covers Image Processing. In this class I am writing filters that could be seen in programs like Photoshop or GIMP. When I finish this project and get through the midterms I have, I want to compare and contrast the different filters using C++ and Python both using the wxWidgets framework.
In Game Logging System
I wrote this code not to long ago in C++. I am using it in a game project I am working on where I want to be able to log information in both Debug and Release mode. I got this idea looking at the Windows Event Viewer and noticed under applications everything has 3 flags, Error, Warning, Information. Errors will output what went wrong at the time of the application crash. Warnings will display something that could become an error. Information is everything else and it fills up the event viewer. At this time I was also reading ‘Game Engine Architecture’ by Jason Gregory which is a fantastic book. I was reading about all of the debugging tools Naughty Dog uses in their engine, which leads me to the logging system.
I wanted to make a system that could meet these requirements:
- Output information in Debug and Release mode
- Output any remaining information in the event of a crash
- Simple easy to use interface for other Developers on the team
- No performance hit
- Output to a file that can be easily read
This is the system I came up with:
class Logger
{
public:
enum Sevarity
{
LOG_ERROR,
LOG_WARNING,
LOG_INFORMATION,
LOG_INPUT,
LOG_SOUND
};
~Logger(void);
void Log(std::string str, Sevarity s);
static Logger* GetInstance(void);
void Initialize(void);
void Update(float deltaTime);
private:
Logger(void);
ThreadData* td;
CRITICAL_SECTION crit;
HANDLE exitEvent;
HANDLE thread;
std::list outputBuffer;
bool active;
static Logger* logInstance;
};
As you can see the system is very simple. Every thing that needs to be logged will go through the Log function. You might notice LOG_INPUT and LOG_SOUND, these were added after I created the system and put it into the engine. The rest of the class if self explanatory. One of the important things I should go over is the use of threads in this system. The way the system works is a thread is running which is responsible for writing to a file and that is all it does. When the Log function gets called it just buffers the output, when the thread awakens it will check this buffer and copy it over to its own memory, that way it wont hold up any functions with a Critical Section. After it has completed the copy it will begin working on writing out to a file. When this is completed it will go back to sleep for a specified amount of time. In the event of a crash or exit it will grab all of the contents of the buffer, write it out to the file, then clean up any loose ends. Here is the function:
/******************************************************************************/
/*!
\author David James
\brief
Thread function that will be used to process logging events
\param data
Typical data that is passed to the thread, in this case ThreadData type
\return
Return state of the thread
*/
/******************************************************************************/
DWORD WINAPI LogThread(void* data)
{
ThreadData* td = reinterpret_cast<ThreadData*>(data);
std::ofstream fileOut;
std::ostringstream filename;
SYSTEMTIME time;
GetLocalTime(&time);
std::list threadList;
filename << "LogFiles\\" << "Log_" << time.wHour << '-' << time.wMinute << ".csv";
fileOut.open(filename.str());
if(fileOut.good())
{
fileOut << "Time Stamp, Severity, String" << std::endl; while(WaitForSingleObject(td->exitEvent, 0) != WAIT_OBJECT_0)
{
EnterCriticalSection(&(*td->crit));
// Copy what is waiting in the buffer to memory the thread can use
//
threadList = *td->output;
td->output->clear();
LeaveCriticalSection(&(*td->crit));
// Write everything in CSV format
//
for(std::list::iterator it = threadList.begin(); it != threadList.end(); ++it)
{
fileOut << (*it).time.wHour << ':' << (*it).time.wMinute << ':' << (*it).time.wSecond << ':' << (*it).time.wMilliseconds << ',' << (*it).severity << ','<< (*it).str << std::endl; }
// Wait 1 second before next write
//
Sleep(1 * 1000);
}
// This code is called in the event of a crash or exit of the application
//
EnterCriticalSection(&(*td->crit));
// Writes everything remaining in buffer
//
for(std::list::iterator it = td->output->begin(); it != td->output->end(); ++it)
{
SYSTEMTIME time;
GetLocalTime(&time);
fileOut << time.wHour << ':' << time.wMinute << ':' << time.wSecond << ':' << time.wMilliseconds << ',' << (*it).severity << ',' << (*it).str << std::endl; } td->output->clear();
LeaveCriticalSection(&(*td->crit));
}
else
{
DebugBreak(); // File failed to open
}
fileOut.close();
return 0;
}
I output this using the .csv file format, this way I can use the tools provided by Microsoft Excel to filter data, after all when the files are done writing some of them can have thousands of lines of information and 3 lines of errors. When all I care about is the error messages and where it broke. You may notice in the code GOLDEN_BITS, this is a define I have set up in Visual Studio. The Golden build mode is when we are ready to ship we will compile in this mode which, provided all of the other devs have been using them, will remove all of the debug and logging calls.
The rest of the Logger is fairly straight forward to implement. Post in the comments below if you have any questions I would be happy to answer them.
